Backtesting
Deploying your app into production is just one step in a longer journey continuous improvement. You'll likely want to develop other candidate systems that improve on your production model using improved prompts, llms, indexing strategies, and other techniques. While you may have a set of offline datasets already created by this point, it's often useful to compare system performance on more recent production data.
This notebook shows how to do this in LangSmith.
The basic steps are:
- Sample runs to test against from your production tracing project.
- Convert runs to dataset + initial experiment.
- Run new system against the dataset to compare.
You will then have a new dataset of representative inputs you can you can version and backtest your models against.
Note: In most cases, you won't have "ground truth" answers in this case, but you can manually compare and label or use reference-free evaluators to score the outputs.(If your application DOES permit capturing ground-truth labels, then we obviously recommend you use those.
Prerequisites
Install + set environment variables. This requires langsmith>=0.1.29 to use the beta utilities.
%%capture --no-stderr
%pip install -U --quiet langsmith langchain_anthropic langchainhub langchain
import os
# Set the project name to whichever project you'd like to be testing against
project_name = "Tweet Critic"
os.environ["LANGCHAIN_API_KEY"] = "YOUR API KEY"
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["ANTHROPIC_API_KEY"] = "YOUR ANTHROPIC API KEY"
os.environ["LANGCHAIN_PROJECT"] = project_name
(Preliminary) Production Deployment
You likely have a project already and can skip this step.
We'll simulate one here so no one reading this notebook gets left out. Our example app is a "tweet critic" that revises tweets we put out.
from langchain import hub
from langchain_anthropic import ChatAnthropic
from langchain_core.messages import HumanMessage
from langchain_core.output_parsers import StrOutputParser
prompt = hub.pull("wfh/tweet-critic:7e4f539e")
llm = ChatAnthropic(model="claude-3-haiku-20240307")
system = prompt | llm | StrOutputParser()
inputs = [
"""RAG From Scratch: Our RAG From Scratch video series covers some important RAG concepts in short, focused videos with code. This is the 10th video and it discusses query routing. Problem: We sometimes have multiple datastores (e.g., different vector DBs, SQL DBs, etc) and prompts to choose from based on a user query. Idea: Logical routing can use an LLM to decide which datastore is more appropriate. Semantic routing embeds the query and prompts, then chooses the best prompt based on similarity. Video: https://youtu.be/pfpIndq7Fi8 Code: https://github.com/langchain-ai/rag-from-scratch/blob/main/rag_from_scratch_10_and_11.ipynb""",
"""@Voyage_AI_ Embedding Integration Package Use the same custom embeddings that power Chat LangChain via the new langchain-voyageai package! Voyage AI builds custom embedding models that can improve retrieval quality. ChatLangChain: https://chat.langchain.com Python Docs: https://python.langchain.com/docs/integrations/providers/voyageai""",
"""Implementing RAG: How to Write a Graph Retrieval Query in LangChain Our friends at @neo4j have a nice guide on combining LLMs and graph databases. Blog:""",
"""Text-to-PowerPoint with LangGraph.js You can now generate PowerPoint presentations from text! @TheGreatBonnie wrote a guide showing how to use LangGraph.js, @tavilyai, and @CopilotKit to build a Next.js app for this. Tutorial: https://dev.to/copilotkit/how-to-build-an-ai-powered-powerpoint-generator-langchain-copilotkit-openai-nextjs-4c76 Repo: https://github.com/TheGreatBonnie/aipoweredpowerpointapp""",
"""Build an Answer Engine Using Groq, Mixtral, Langchain, Brave & OpenAI in 10 Min Our friends at @Dev__Digest have a tutorial on building an answer engine over the internet. Code: https://github.com/developersdigest/llm-answer-engine YouTube: https://youtube.com/watch?v=43ZCeBTcsS8&t=96s""",
"""Building a RAG Pipeline with LangChain and Amazon Bedrock Amazon Bedrock has great models for building LLM apps. This guide covers how to get started with them to build a RAG pipeline. https://gettingstarted.ai/langchain-bedrock/""",
"""SF Meetup on March 27! Join our meetup to hear from LangChain and Pulumi experts and learn about building AI-enabled capabilities. Sign up: https://meetup.com/san-francisco-pulumi-user-group/events/299491923/?utm_campaign=FY2024Q3_Meetup_PUG%20SF&utm_content=286236214&utm_medium=social&utm_source=twitter&hss_channel=tw-837770064870817792""",
"""Chat model response metadata @LangChainAI chat model invocations now include metadata like logprobs directly in the output. Upgrade your version of `langchain-core` to try it. PY: https://python.langchain.com/docs/modules/model_io/chat/logprobs JS: https://js.langchain.com/docs/integrations/chat/openai#generation-metadata""",
"""Benchmarking Query Analysis in High Cardinality Situations Handling high-cardinality categorical values can be challenging. This blog explores 6 different approaches you can take in these situations. Blog: https://blog.langchain.dev/high-cardinality""",
"""Building Google's Dramatron with LangGraph.js & Claude 3 We just released a long YouTube video (1.5 hours!) on building Dramatron using LangGraphJS and @AnthropicAI's Claude 3 "Haiku" model. It's a perfect fit for LangGraph.js and Haiku's speed. Check out the tutorial: https://youtube.com/watch?v=alHnQjyn7hg""",
"""Document Loading Webinar with @AirbyteHQ Join a webinar on document loading with PyAirbyte and LangChain on 3/14 at 10am PDT. Features our founding engineer @eyfriis and the @aaronsteers and Bindi Pankhudi team. Register: https://airbyte.com/session/airbyte-monthly-ai-demo""",
]
_ = system.batch(
[{"messages": [HumanMessage(content=content)]} for content in inputs],
{"max_concurrency": 3},
)
Convert Prod Runs to Experiment
The first step is to generate a dataset based on the production inputs. Then copy over all the traces to serve as a baseline run.
convert_runs_to_test is a function which takes some runs and does the following:
- The inputs, and optionally the outputs, are saved to a dataset as Examples.
- The inputs and outputs are stored as an experiment, as if you had run the
evaluatefunction and received those outputs.
from datetime import datetime, timedelta, timezone
from langsmith import Client
from langsmith.beta import convert_runs_to_test
# How we are sampling runs to include in our dataset
end_time = datetime.now(tz=timezone.utc)
start_time = end_time - timedelta(days=1)
run_filter = f'and(gt(start_time, "{start_time.isoformat()}"), lt(end_time, "{end_time.isoformat()}"))'
# Fetch the runs we want to convert to a dataset/experiment
client = Client()
prod_runs = list(
client.list_runs(
project_name=project_name,
execution_order=1,
filter=run_filter,
)
)
# Name of the dataset we want to create
dataset_name = f'{project_name}-backtesting {start_time.strftime("%Y-%m-%d")}-{end_time.strftime("%Y-%m-%d")}'
# This converts the runs to a dataset + experiment
# It does not actually invoke your model
convert_runs_to_test(
prod_runs,
# Name of the resulting dataset
dataset_name=dataset_name,
# Whether to include the run outputs as reference/ground truth
include_outputs=False,
# Whether to include the full traces in the resulting experiment
# (default is to just include the root run)
load_child_runs=True,
)
Benchmark new system
Now we have the dataset and prod runs saved as an experiment.
Let's run inference on our new system to compare.
from langsmith import evaluate
def predict(example_input: dict):
# The dataset includes serialized messages that we
# must convert to a format accepted by our system.
messages = {
"messages": [
(message["type"], message["content"])
for message in example_input["messages"]
]
}
return system.invoke(messages)
# Use an updated version of the prompt
prompt = hub.pull("wfh/tweet-critic:34c57e4f")
llm = ChatAnthropic(model="claude-3-haiku-20240307")
system = prompt | llm | StrOutputParser()
test_results = evaluate(
predict, data=dataset_name, experiment_prefix="HaikuBenchmark", max_concurrency=3
)
Review runs
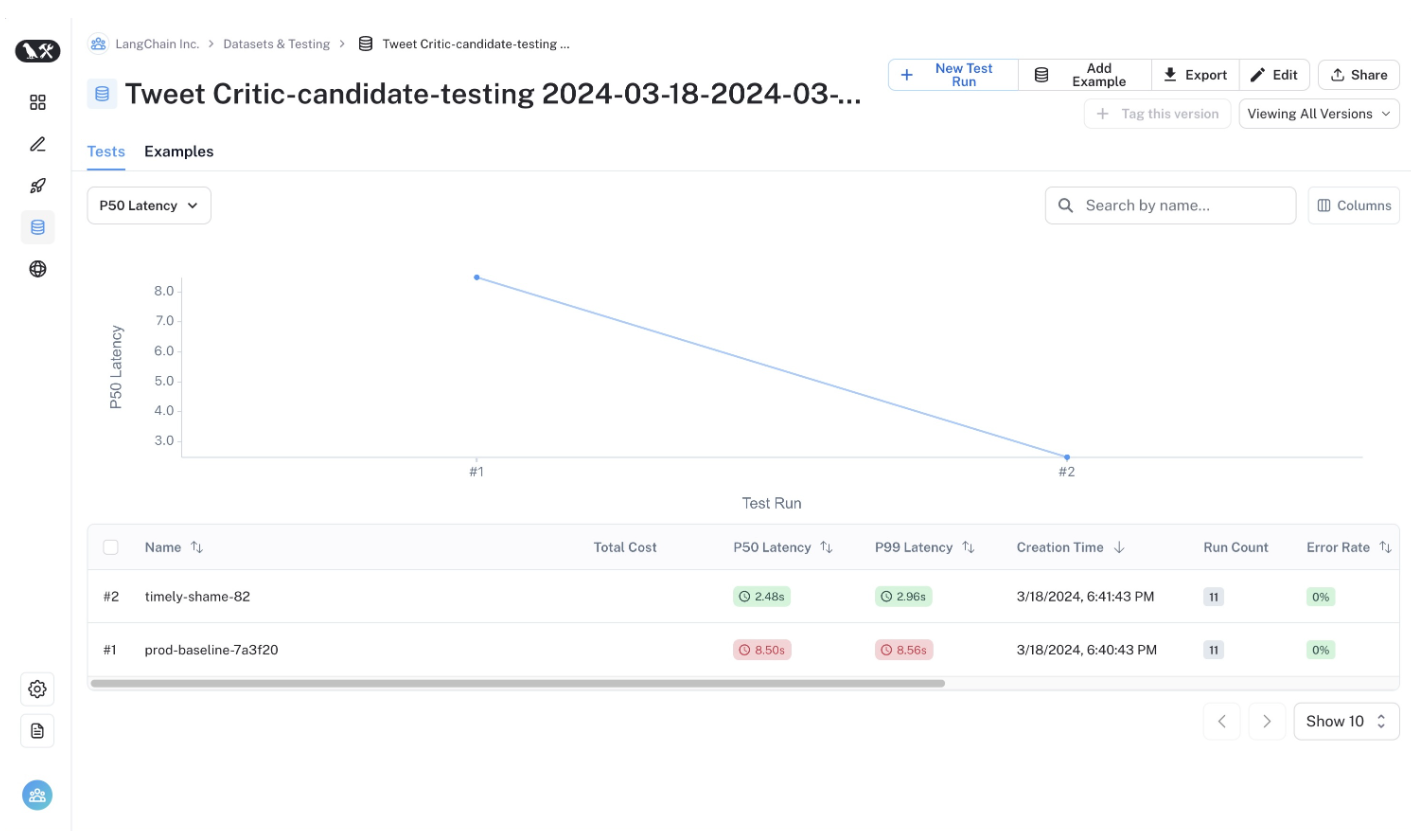
You can now compare the outputs in the UI.
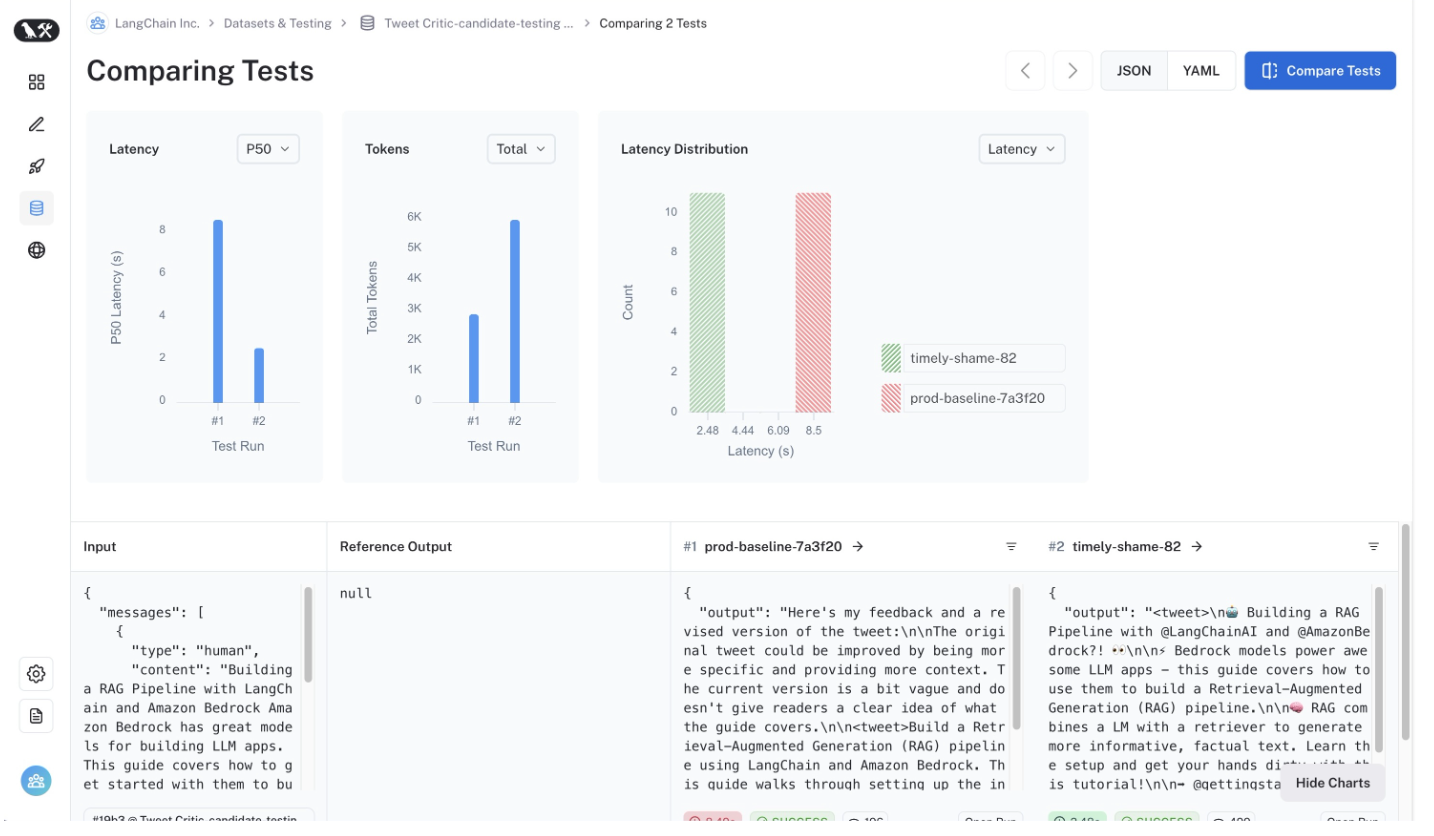
Conclusion
Congrats! You've sampled production runs and started benchmarking other systems against them. In this exercise, we chose not to apply any evaluators to simplify things (since we lack ground-truth answers for this task). You can manually review the results in LangSmith and/or apply a reference-free evaluator to the results to generate metrics instead.